High-quality Instance-aware Semantic 3D Map Using RGB-D Camera
2019.11 瑞典厄勒布鲁大学,RGBD语义SLAM,indoor,TUM ,YCB vedio dataset
论文总结:
本文选择了分割网络中的性能最好的MASK RCNN和SLAM系统中性能最好的ELAstic fusion作为骨干网络,并且在MASKRCNN的网络中加入了新的分支,这样庞大的结构基本上就和实时说再见了,但是换来的收益是与SOTA比肩的追踪性能和超越SOTA的重建性能,可以说是有舍有得。
本文所提出的系统表明,通过将外观和语义两条线索与相机姿态跟踪中的自适应权重相结合,就能够在小尺度环境中获得可靠的相机跟踪和最精确的曲面重建。
论文摘要
本文提出的模型能够在室内 room-sized 环境下对实例级别的语义模型进行建模。
使用Elasticfusion作为backbone,对其损失函数进行了修改,并将深度学习中的分割和检测模型加入到RGBD-slam中,使得系统能够重建语义模型以及提供精确的语义地图
论文简介
本文方法结合了SOTA的RGBD SLAM和基于深度学习的分割网络的优点,设计了一个优于原本Mask RCNN的CNN网络,并为位姿估计中的损失函数输出一个可学习的权重。
现有方法大都是为每个面元/体素输出维护一个概率,而本文方法通过实例标签降低了空间复杂度。
除了高精度的语义场景重建,还通过提出的两个标准纠正了误分类的区域。标准基于局部信息和像素的类别概率
本文研究方法
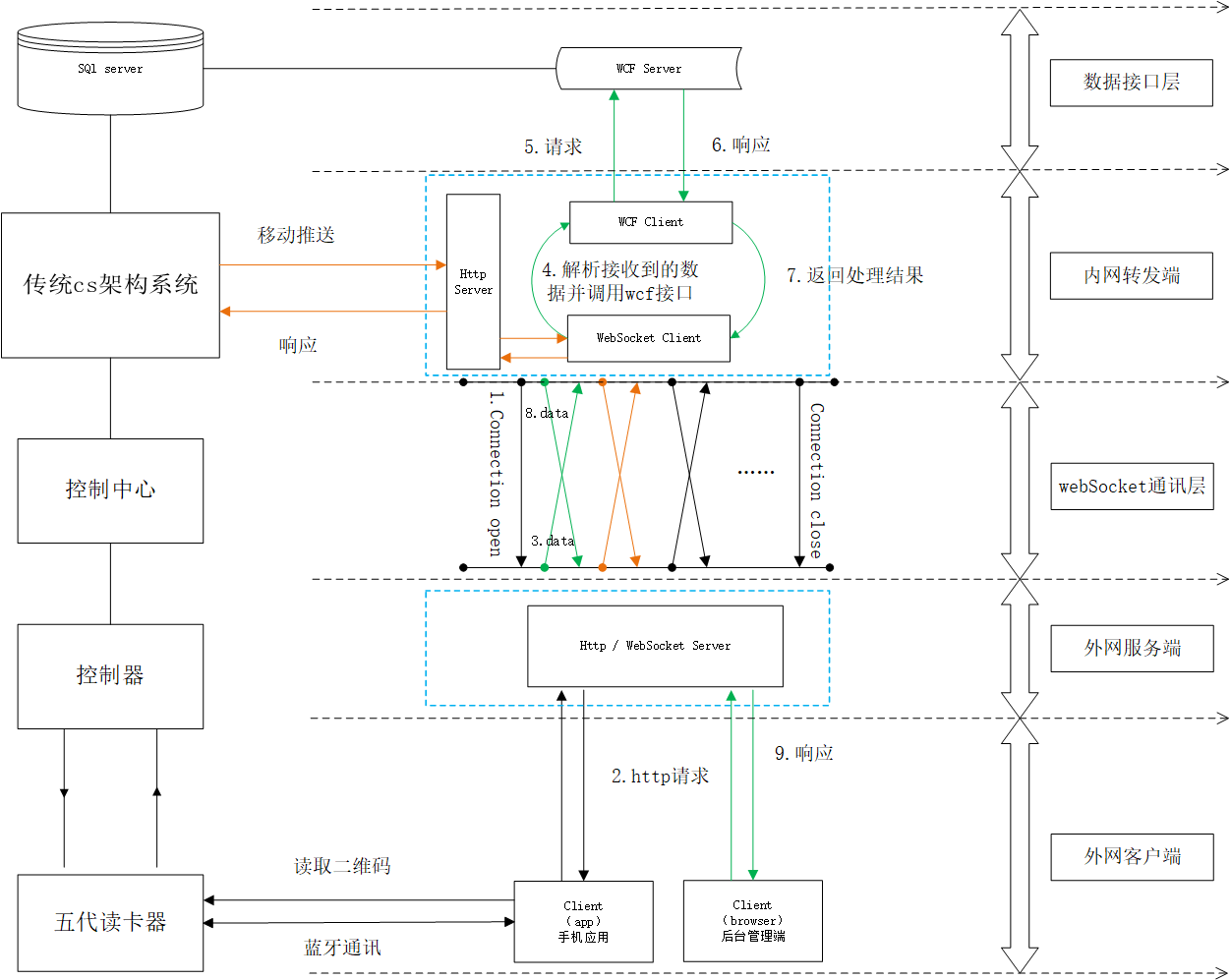
整体结构如图:

输入数据(RGBD)->语义分割网络 -> 位姿估计 -> 融合提升
-
分割网络
使用CNN架构生成带有语义标签的目标掩码。改进后的网络还预测输出了像机跟踪损失函数的权重。
在MaskRCNN的基础上进行改进,CNN输出的特征图通过一个额外的FCN分支输出损失函数中要用到的权值。
权值给估计过程被当作一个分类任务来做:最终的决策是一个二值的决策,即该RGB图像是否将在registration process中被使用。因此权值估计过程是在决定该RGB图像是否包含有效的信息。

-
相机追踪
使用提出的联合损失函数,在Elastic fusion中输出相机的预测位姿。将几何和光度估计的损失函数合并成一个加权和。通过上述分割过程,生成彩色图像的自适应权值。
这里使用Elasticfusion作为SLAM 系统,每个面元存储了坐标,法向量,颜色,权值,半径,时间戳,此外还有一个实例标签。
mask分支生成一个M x M 的浮点数mask,然后mask被resize到ROI的尺寸,通过0.5的阈值二值化后,得到一个逐像素的非背景概率地图,尺寸大小是480*640。在时间t的RGBD帧,其每个像素都被分配一个非背景概率 po(It)。相机追踪和3D重投影使得每个面元的概率可以由一下公式得到:
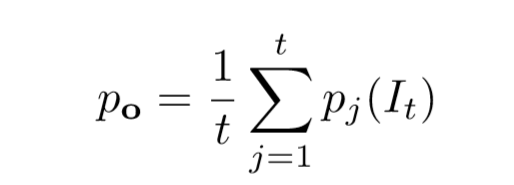
-
融合提升分割效果
将基于实例的语义融合将分割信息融合到三维地图中。为了提高分割精度,采用两种基于CNN预测序列的准则对错误分类区域进行校正。
事实上MASk RCNN 将常会有错误分割,细节丢失或平滑的现象。因此分割过程有很多可以提升的地方。基于很多被误分类的像素的非背景概率仅小于0.5但是非常接近0.5,这里提出对非背景概率小于0.5的像素的两个准则 :
- 像素点的非背景概率大于0.4
- 像素点的6个领域中至少有一个是目标像素(非背景像素)
为了优化分割结果,对每个满足以上第一个准则的像素点(即0.4-0.5)维护一个置信度ϑ(s),第一次观测到的面元置信度置为0,然后在之后的帧中每观测到一帧,对满足以上两个准则的面元置信度+1。
n 帧之后,若置信度超过阈值,则将面元s分配到最近的一个实例,否则将置信度置为0.(n=10,阈值=10)
实验结果
环境配置:
GTX 1080 Ti 6GB GPU
i7-4770K 3.5GH
输入数据:640×480 resolution RGB-D
1. 相机追踪实验
baseline:MaskFusion ,Fusion++ 
性能超越mask fusion 和 fusion++,比elasticfusion 略低
2.重建实验
论文强调了一个擅于追踪相机位姿的系统一般不善于高精度的表面重建。 
在重建任务中本文方法全面超越了elastic fusion,作者将其归结为引入了有可学习权值的联合损失函数的原因 ,并且在本文模型中,每个实例的面元都是激活的,但是在elasticfusion中面元没有被观测到一段时间就会被设置为未激活,这导致本文方法的重建精度更加优越
3.分割精度实验
通过将重建的3D模型重投影获得2D分割MASK,性能相比MASK RCNN 提升明显

4.速度和内存占用
由于巨大的计算量,不能实时。
CNN:350ms
camera pose estimation, fusion, and segmentation require a further 70ms
内存占用对比实验:

The average memory usage of the proposed method is 5.7% of those conventional approaches.
内存占用下降明显